Friedman Test
A Statistical Comparisons of Classifiers over Multiple Data Sets
Introduction
The objective of this assignment is to perform a robust statistical comparison of multiple machine learning classifiers across several independent datasets. When evaluating more than two models over multiple datasets, traditional parametric tests such as the Analysis of Variance (ANOVA) are often unsuitable. This is because the assumptions of a normal distribution and homogeneity of variance are frequently violated by classification accuracy scores. To address this, we employ the Friedman test, a non-parametric (distribution-free) alternative, which rather than analyzing raw performance scores, operates on the relative ranks of the algorithms.
Nemenyi Post-Hoc Test
Datasets
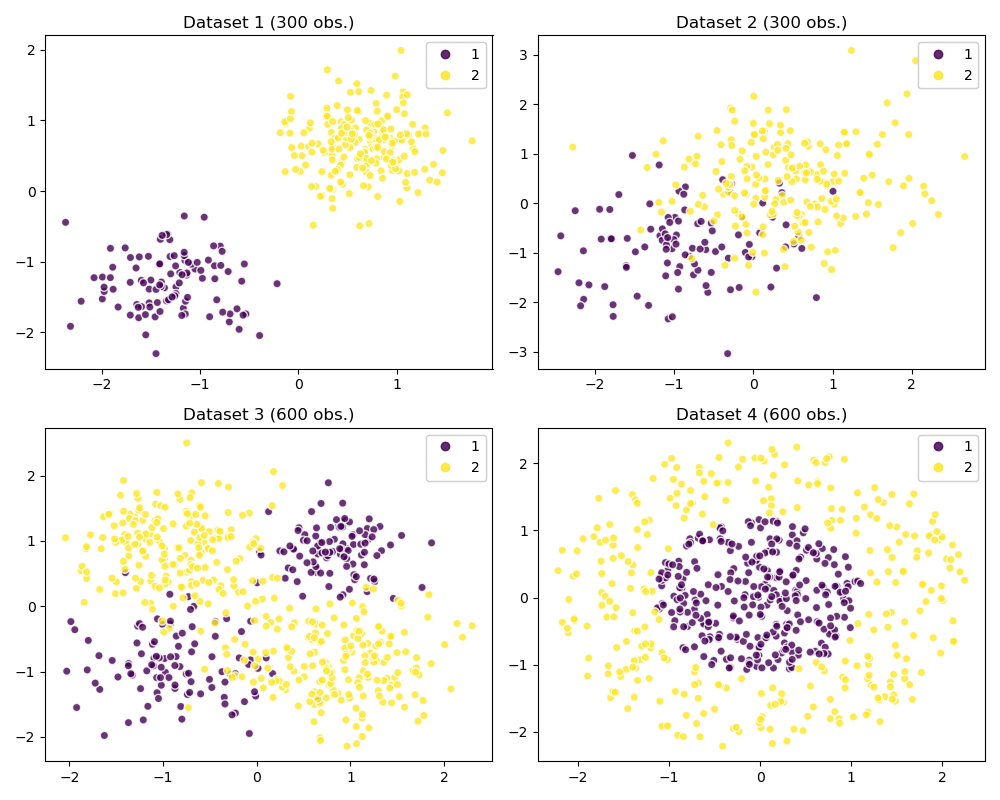
Models
Evaluation Protocol
Results and Discussion
Loading table...
Critical Difference
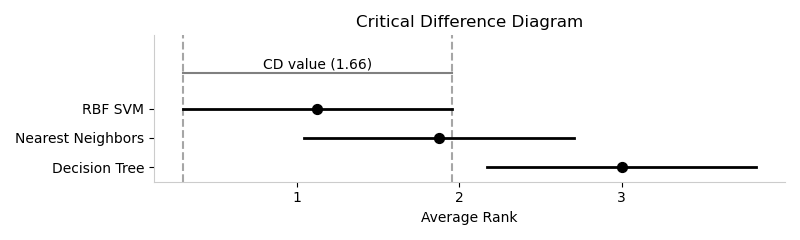
is the Critical Difference diagram
Conclusion
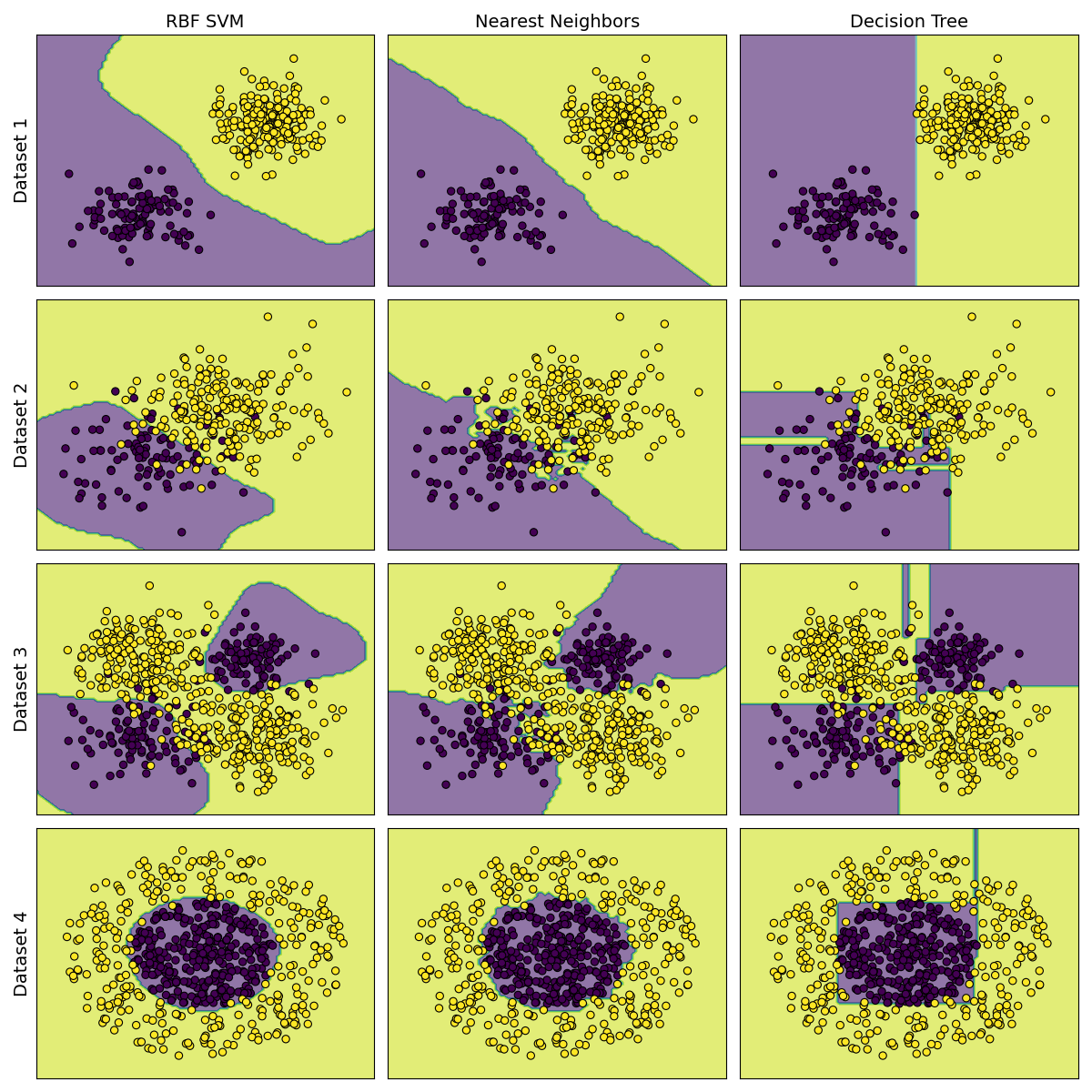
According to research , notes are vital.
References
Loading bibliography...